G5 integration
Raw files are imported in database with the following commands :php run-g5.php gauq A raw2tmp small php run-g5.php gauq A tweak2tmp php run-g5.php gauq A addGeo small php run-g5.php gauq A legalTime php run-g5.php gauq A tmp2dbInput data are a copy of Cura html pages, located in
data/raw/gauq/lerrcp/.
Step
raw2tmp convert these html pages to CSV files stored in data/tmp/gauq/lerrcp.
Steps
tweak2tmp, addGeo and legalTime bring corrections to these tmp files.
Step
tmp2db finally imports the corrected tmp files in database.
raw2tmp
The main task of this command is to merge the two lists (list with names and list with precise birth data) ; see next paragraph.This command needs a parameter to indicate what it should print :
php run-g5.php gauq A1 raw2tmp
MISSING PARAMETER : raw2tmp needs a parameter to specify which output it displays. Can be : small : echoes only global results full : prints the details of problematic rows
Profession codes
In some files of serie A, the precise profession codes are not associated to the records. This is possible to fix thanks to the notices that are present on Cura pages.These informations were included to the program (see constant
PROFESSIONS_DETAILS of class g5\commands\gauq\A\A) ; each record is associated to its precise profession in the resulting csv file.
Small errors
902gdA1y.html
-
in page
902gdA1y.html, there is an incoherence between the two lists for one record :1817 3 25 C 185 F 5 16 24 0 48N 0 4W 6 29 CONCARNEAU
and1817 3 5 Lebris Jean
Birth certificate permits to solve the case.
Online civil registry : Registre 1 MI EC 53/10 Naissances, p 377 / 559 => "Né ce jour en cette ville à cinq heures du matin"
=> date =1817-03-25 05:00
Check if it matches UT time given by Cura :
From "Traité de l'heure dans le monde", TU = HLO ; 4°6' = 00:16:24 => hour = 05:16:24
OK => The first line is exact, the second line must be replaced by1817 3 25 Lebris Jean
This fix is included in the code ofraw2tmp.
{kind=link}
NUM with exclamation marks
Some records of serie A have a ! in their NUM :A1 : 909 1876 A2 : 2641 A4 : 159 320 439 1350 1443 1480 2136 2312 A5 : 1435 1557 1813 1829 2349 A6 : 15 139 148 225 232 265 448 574 622 668 718 727 737 738This is not present in pages including names (for example present in 902gdA1.html but not in 902gdA1y.html).
The explanation is given in main Cura page : they correspond to records containing errors in the original publication (LERRCP), and corrected in Françoise Gauquelin's journal Astro-Psychological Problems.
This information is not yet included in g5 database.
Name restoration
This problem is handled by stepraw2tmp
Each page of serie A contain 3 lists :
- One list with precise birth data, but without names.
- Two lists with names, but without precise birth data ; these two lists are sorted differently. I supposed (but didn't check by program) that these two lists are equivalent.
The purpose is to obtain records containing both precise birth data and the name of the person.
To summarize, this can be partially done by program from cura.free.fr web pages ; some cases can be fixed by human using Gauquelin 1955 book.
raw2tmp matching could be bettered for some cases, using newalchemypress.com data. See below, paragraphs Use Ertel 4391 and Use Müller 1083.
Merge lists
The program must merge the two lists.A check done by program
php run-g5.php cura A look listsshows that list with precise birth data differ from lists with names (lists with names contain less persons), so a trivial merge is not possible.
Unfortunately, these 2 lists don't share a common unique identifier which would permit to merge without ambiguity.
These two lists have in common the birth day. This was used to perform the merge, but a given birth day can correspond to several persons. In this case, ambiguity remains, and can't be solved by program.
To solve some ambiguities, Gauquelin 1955 book was used in an iterative process :
- Build two arrays with birth day as key.
- Merge the clear cases, with only one person for a given day.
- Print the ambiguous cases.
- Look in Gauquelin 1955 book if the ambiguous persons are present.
- Inject the information in the program (constant
CORRECTIONS_1955in classg5\commands\cura\A\A). - Execute again.
For the cases that could not be solved, a name like "Gauquelin-A1-1352" was built, using file name and NUM field.
The results of this name matching are :
| Serie | OK | Not OK |
|---|---|---|
| A1 | 1968 (94.3 %) | 119 (5.7 %) |
| A2 | 3436 (94.32 %) | 207 (5.68 %) |
| A3 | 2640 (86.67 %) | 406 (13.33 %) |
| A4 | 2486 (91.4 %) | 234 (8.6 %) |
| A5 | 2184 (90.62 %) | 226 (9.38 %) |
| A6 | 1262 (62.29 %) | 764 (37.71 %) |
| TOTAL | 13 976 (87.72 %) | 1956 (12.28 %) |
Benefit from other files
Fortunately, name restoration can be bettered because other files contain common records :| External file | Cura files |
|---|---|
| Ertel 4391 sportsmen | A1 |
| Müller 1083 physicians | A2 |
| Müller 402 writers | A1, A2, A4, A6 |
| Gauquelin 1955 | A1, A2, A3, A4, A5, A6 |
Name fixes coming from Ertel file is done with this command :
php run-g5.php ertel sport fixA1 updateIt permits to restore 100 % of names not identified by step
raw2csv in A1.
See page on Ertel 4391, paragraph "Fix cura A1 names".
NB :
raw2csv leaves 118 names unidentified and this step restores 117. This is because one name is handled by step tweak2tmp.
Name fixes coming from Arno Müller's file of 1083 medical doctors is used to better names and birth days in A2.
This permits to fix only 12 unidentified names in A2.
See page on Müller 1083, paragraphs "Fix Gauquelin names" and "Fix Gauquelin days".
tweak2tmp
Auxiliary YAML files located indata/db/init/lerrcp-tweak permit to store corrections used to solve errors detected in steps addGeo and legalTime.
addGeo
This step brings corrections to place names and compute geonames id for non-ambiguous cases.It is useful for several purposes:
- Correct city names, which are approximative in Cura web pages.
-
Add precision to longitudes, which is useful for legal time computation.
Longitudes given in Cura web page are precise to 1 arc minute, and are sometimes erroneous.
See for example record A1-558 Charles Farroux ; longitude given by Cura is 2°05', and geonames gives 2°59'59'' - Prepare matching with wikidata.
This command needs a parameter to indicate what it should print :
php run-g5.php gauq A1 addGeo
WRONG USAGE - This command needs a parameter indicating the type of report - full : lists all the place names that can't be matched to geonames. - medium : lists the places with several matches to geonames. - small : only echoes global information about matching.It modifies records of
data/tmp/gauq/lerrcp/ only if there is a unique match to geonames. This restrictive match gives low matching rates but guarantees that the command doesn't introduce errors.
In case of match, fills column
GEOID, and updates column PLACE (because place names in geonames are generally better).
See page about Geonames.
The problem of time
Gauquelin data available on Cura web pages are sometimes given in a format that generates a problem.This problem occurs in all files of series A, B, F, NH, and in files D9a, D9b, D9c. Hopefully, D6, D10, E1, E3 are not concerned.
For example, record n° 798 of file A1 is given like this in cura.free.fr :
YEA MON DAY PRO NUM COU H MN SEC TZ LAT LON COD CITY (...) 1909 3 14 C 798 F 4 50 40 0 48N 0 4W 6 29 PLEYBENThis means that birth time is
04:50:40 and that timezone offset = 0.
This can be compared with a scan of Gauquelins' LERRCP publication provided in cura.free.fr ; it shows that the same record was given in a different form :
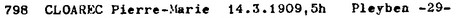 This means that birth time is
This means that birth time is 05:00:00, and timezone offset is not provided.
Cura's value
04:50:40 is the result of a computation : legal time - timezone offset.
This is coherent with the notice found in Cura A1 page : Birthtime is converted to standard time, either for zone 0 (= GMT) or -1 (= CET) The way birth times are expressed in cura site adds information (the timezone offset). It's cool because the information can be directly used to compute birth chart.
But expressing times this way should be avoided because two distinct informations are mixed in one field :
- The legal time, as it can be read in civil registries.
- The timezone offset.
Doing like that generates a loss of information.
If the data is not correct, it is not possible to answer to the question : does it come from an error on legal time or on timezone offset computation ?
Restoring legal time
The command :php run-g5.php cura A legalTimeadds two columns,
DATE-C (= date corrected) and TZO (timezone offset) to the tmp files of data/tmp/gauq/lerrcp.
Current code performs restoration only for persons born in France, excluding all cases that can't be fixed by program without ambiguity (ambiguity comes from world wars 1 and 2, for parts of France that were invaded by Germany ; precise timezone offset depend on local conditions ; see page about timezone).
Example for record A1-1 Alard Pierre
Information extracted from Cura file gives
DATE-UT = 1937-09-17 17:00:00
Command
legalTime adds 2 columns:
DATE-C = 1937-09-17 18:00
TZO = +01:00
This is OK, but a problem appears in France for dates prior to 1891-03-15 because timezone offset computation involves longitude:
Example for record A1-2 André Georges
Information extracted from Cura file gives
DATE-UT = 1889-08-13 12:20:40
Command
legalTime adds 2 columns:
DATE-C = 1889-08-13 12:30:04
TZO = +00:09:24
Here birth time is obviously
12:30 and not 12:30:04.
A probable explanation is that longitudes given in Cura files are not precise enough to permit an exact computation.
If this hypothese is correct, it means that UT times given in Cura pages are not exact. Fortunately, this error is small (max observed = 3 minutes of time), but it is an illustration of the problems generated when providing UT times instead of legal times.
This can be fixed by program (infer correct legal time and recompute timezone offset), but has not been implemented yet.
Restoration rates are low :
A1 : restored 1029 / 2087 dates (49.31 %) A2 : restored 1614 / 3643 dates (44.3 %) A3 : restored 1003 / 3046 dates (32.93 %) A4 : restored 2333 / 2720 dates (85.77 %) A5 : restored 882 / 2410 dates (36.6 %) A6 : restored 776 / 2026 dates (38.3 %)